

Movies Visual Features Extracted (MoViFex) Dataset
A comprehensive dataset of visual features extracted from movies in various formats, including full movies, movie shots, and trailers.
About the Dataset
The MoViFex dataset is a comprehensive collection of visual embeddings extracted from movies in various aspects. It is designed to facilitate research in the field of movie recommendation and related areas.
Check the DetailsHierarchical Visual Embeddings
Explore visual features extracted at three distinct levels: full-length movies, individual movie shots, and trailers. This milti-level data design supports granular or holistic analysis, catering to diverse applications.
Various Feature Extractors
Use the features extracted using state-of-the-art Convolutional Neural Networks (CNNs), including Inception-v3 and VGG19, providing rich and varied visual representations.
Dissimilar Spatial Dimensions
Choose between Atomic (frame-level) features for detailed study or aggregated representations for higher-level insights.
Versatile Applications
Designed for versatility, the dataset empowers tasks such as movie recommendation, scene analysis, video classification, visual storytelling, etc.
Stats
Total Number of Movies
Average Frames Extracted per Movie
Total Number of Frames
Average Movie Ratings (exact: 3.88/5.0)
Total Number of Users
Total Number of Interactions
Details
| Aspect | Value |
|---|---|
| Total number of movies | 274 |
| Average frames extracted per movie | 7,732 |
| Total number of frames (or feature vectors) | 2,118,647 |
| Accumulative number of genres | 723 |
| Average movie ratings | 3.88/5.0 |
| Total number of users | 158,146 |
| Accumulative number of interactions | 2,869,024 |
Level I. Primary Categories
The dataset is organized into six folders and a stats.json file containing the meta-data for the sources. It is collected from 274 movie videos, where the identifiers and meta-data of the movies are obtained from the MovieLenz-25M dataset. The visual frame (and therefor, feature) extraction rate is 1 FPS.
- full_movies containing the visual features extracted from full-length movies (frame-level)
- movie_shots containing the visual features extracted from full-length movies' shots (shot-level)
- movie_trailers containing the visual features extracted from movie trailers (frame-level)
- full_movies_agg containing the aggregated embeddings extracted from full-length movies
- movie_shots_agg containing the aggregated embeddings extracted from full-length movies' shots
- movie_trailers_agg containing the aggregated embeddings extracted from movie trailers
Level II. Visual Feature Extractors
Inside each folder, there are two folders titled incp3 and vgg19, referring to the feature extractor used to generate the visual features, i.e., Inception-v3 (GoogleNet) and VGG-19, respectively.
- [sample]: Inception-v3 and VGG-19 extracted from full-length movies
Level III. Contents (Movies & Trailers)
A: Atomic Features (e.g., full_movies)
Regarding the Atomic visual features (frame- and shot-level), (i.e., full_movies, movie_shots, and movie_trailers), each embedding folder (e.g., /incp3 or /vgg19) contains a set of folders with unique title (e.g., 0000008985) indicating the movie-id in MovieLenz-25M dataset. Each folder has a set of packet files, which will be further discussed in the next section.
B: Aggregated Features (e.g., full_movies_agg)
Regarding the aggregated visual features, (i.e., full_movies_agg, movie_shots_agg, and movie_trailers_agg), each embedding folder (e.g., /incp3 or /vgg19) contains a a set of JSON files with unique titles (e.g., 0000002023) indicating the movie-id in MovieLenz-25M dataset. Each JSON file has a set of embeddings, aggregated using Maximum and Mean methods.
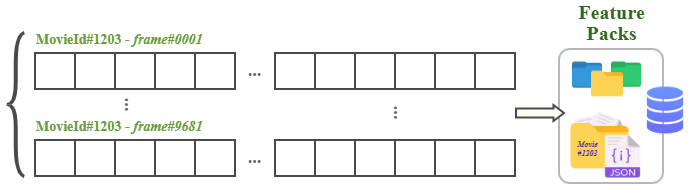
Level IV. Packets (Atomic Feature Folders)
To better organize visual features, each movie folder (e.g., 0000001997) has a set of packets named as packet0001.json to packet000N.json in JSON format. Each packet contains a set of objects with frameId and embeddings. In general, every 25 object (frameId-embedding pair) form a packet, except the last packet that can have less objects.
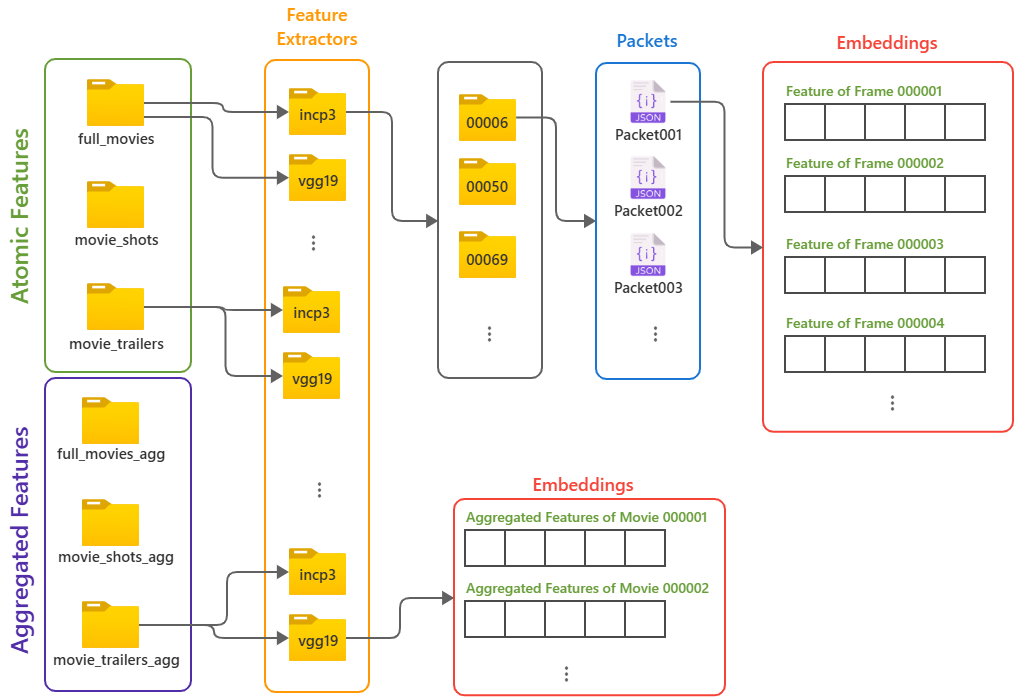
Dataset File Structure
The dataset is structured in a hierarchical manner, where the top-level folders represent the primary categories of the data. Each folder contains the visual features extracted using different CNN models, i.e., Inception-v3 and VGG-19. The extracted features are stored in the form of packets, each containing a set of frame-level embeddings. You can see the data structure in the image on the left.
Download
Note#1
The dataset is comprehensive due to providing thousands of visual features. Hence, you can consider downloading the whole or a portion of it.
Note#2
The dataset can be downloaded directly or accessed via the HuggingFace link for easier integration (read more).
Required Space
The detailed size and specifications of the dataset are outlined in the table below.
| Feature Type | Total File Count | Size on Disk | ||
|---|---|---|---|---|
| Inception-3.0 | VGG-19 | Inception-3.0 | VGG-19 | |
| Full Movies (Atomic) | 84,872 | 84,872 | 35.8 GB | 46.1 GB |
| Movie Shots (Atomic) | 16,713 | 24,598 | 7.01 GB | 13.3 GB |
| Trailers (Atomic) | 1,725 | 1,725 | 681 MB | 885 MB |
| Full Movies (Aggregated) | 84,872 | 84,872 | 10 MB | 19 MB |
| Movie Shots (Aggregated) | 16,713 | 24,598 | 10 MB | 19 MB |
| Trailers (Aggregated) | 1,725 | 1,725 | 10 MB | 19 MB |
| Total | 214,505 | ~103.9 GB | ||
Benchmark
Metadata Analysis
Working with the meta-data JSON file for a general analysis.
Check the Code in ColabDataset Instances
Working with the dataset instances (frame-level extracted visual features) for various tasks.
Check the Code in ColabDataset Instances
Working with the dataset instances (aggregated visual features) for various tasks.
Check the Code in ColabTeam

Ali Tourani
Doctoral Researcher - SnT, University of Luxembourg
Yashar Deldjoo
Tenure-Track Assistant Prof. - Polytechnic University of Bari